一、问题说明
IIS(7/8/10)服务器上由于网站改版需要,可能对特定页面或者全站对指定的蜘蛛屏蔽或者通过(非蜘蛛不让通过),或者是对垃圾蜘蛛屏蔽,都可以用这种方法.
二、解决办法
首先安装IIS的URL重写模块,安装方法参考:IIS7/8/10安装URL重写工具方法
先说第一种,屏蔽垃圾蜘蛛和爬虫,选择需要屏蔽蜘蛛的IIS网站,然后右侧打开URL重写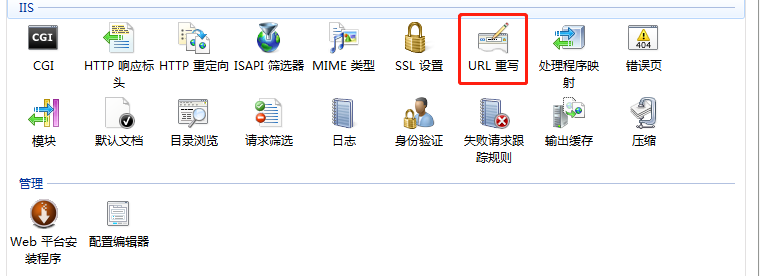
右上角点添加规则,创建一个空白规则
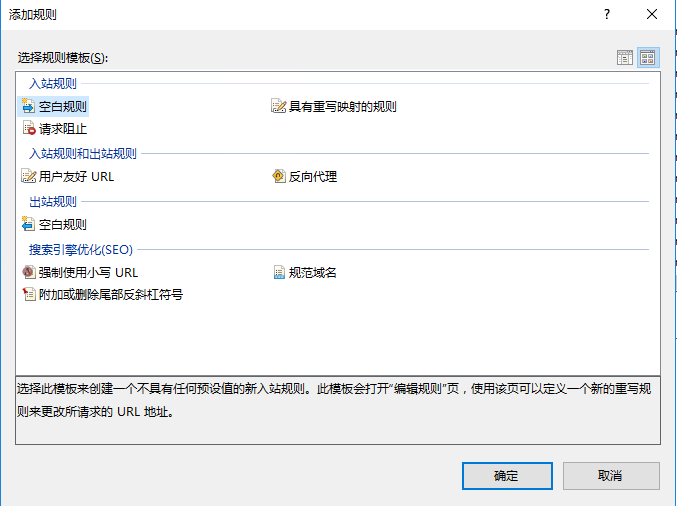
然后名称可以写StopSpiderWorm,匹配URL-模式写.*代表匹配全站(写*也可以)(正则表达式下^$代表首页),如果想屏蔽指定页面/指定目录和其他匹配模式请自行修改
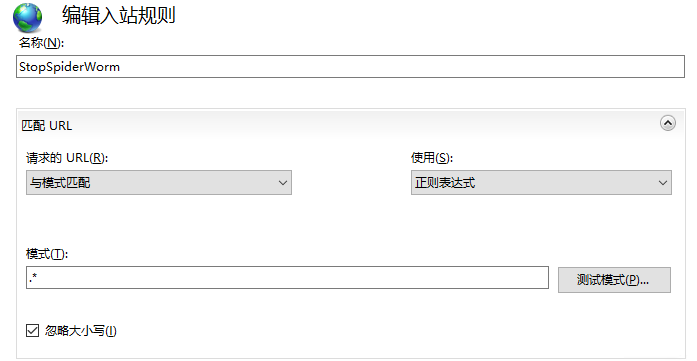
然后展开条件,点击添加,条件输入{HTTP_USER_AGENT}用来匹配蜘蛛UA头,模式里写(每个|代表一条新的规则,需要屏蔽多个蜘蛛头请反复添加写多个条件规则,模式里不需要带|符号,请无视下图的模式写法)(PS:如果不信邪可以全部都写进去点测试模式,本人测试没法正常匹配,IIS好像不认|这个符号,nginx可以用|代表多个条件,也许IIS的正则写法有不同的写法,本人暂时没发现一条可以匹配多个条件的写法)
*AhrefsBot*|*DotBot*|*SemrushBot*|*Uptimebot*|*MJ12bot*|*MegaIndex.ru*|*ZoominfoBot*|*Mail.Ru*|*SeznamBot*|*BLEXBot*|*ExtLinksBot*|*aiHitBot*|*Researchscan*|*DnyzBot*|*spbot*|*YandexBot*
需要其他条件和匹配模式请自行修改
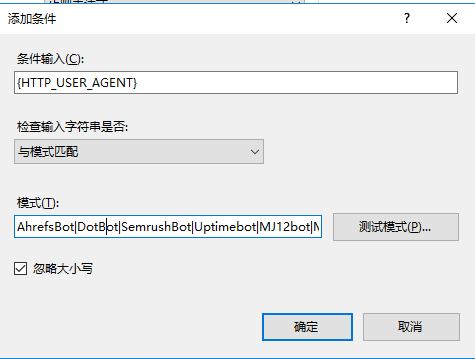
然后再添加条件写爬虫UA头,条件输入{HTTP_USER_AGENT},模式里写(同上面的规则,需要添加多条,请无视图里的模式写法)
*Python*|*Go-http-client*|*HttpClient*|*Java*|*Xenu*
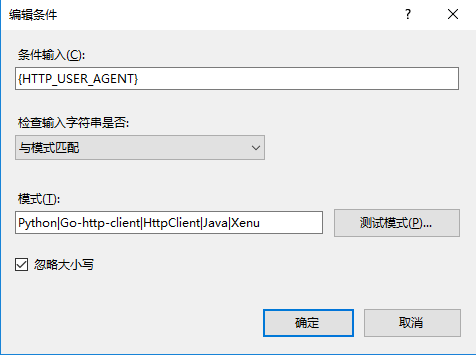
然后修改一下逻辑分组为任意匹配,代表只要匹配到任意一个符合的UA头条件就成立,当然也可以把所有UA头写在一个条件里就不需要修改逻辑分组(逻辑与逻辑或的区别,懂的都懂)
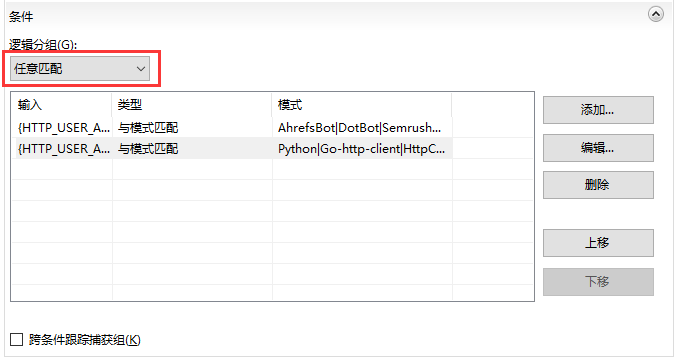
然后修改一下操作为中止请求

最后点击一下右上角的应用就可以保存规则阻断垃圾蜘蛛和爬虫访问网站.
如果是直接请求服务器的,匹配到指定的垃圾蜘蛛和爬虫UA就会从TCP层阻断请求了,但是如果网站通过了CDN,用户UA头包含了上面的UA就会出现520的CDN回源错误页面.(前提是访问的页面没有开缓存回源)
针对这种情况,我们可以使用自定义响应来处理,返回一个403,404之类的HTTP状态代码,子状态代码没搞懂怎么用,就默认0了,然后原因和错误描述写了个提示说明,我以为打开页面可以看到这个说明.
结果并没有看到原因和错误描述,倒是使用curl请求的时候在header头的状态码后面看到了原因的内容,错误描述依旧没有见到.所以可以都写成0也行.空着的话不让应用提交规则.
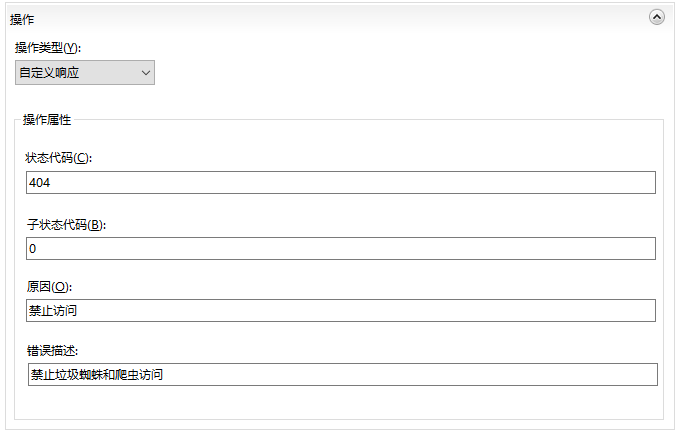
这里单独说明几个特殊的HTTP状态代码118/337/444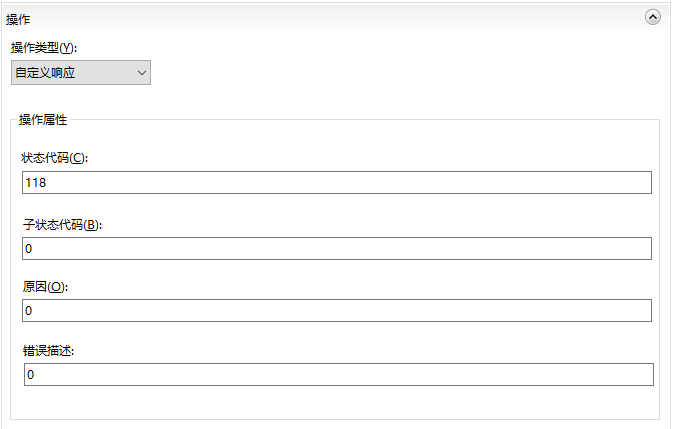
118状态可以通过CDN转发直接让用户收到这个状态码,页面直接无法打开.
337状态也可以通过CDN转发直接让用户收到这个状态码,会打开一个没有内容的空白页.
444状态在nginx可以使用,也是用于阻断用户请求,但是IIS上使用会出现一个提示页:自定义错误模块不能识别此错误。
具体这些HTTP状态代码可能作用的网络层不同,也许可能跟服务端软件以及客户端浏览器不同会出现不同的表象.没有去深究原理.
遇到网站改版,可能只需要蜘蛛正常访问,需要阻断用户访问,可以这么操作(没写的就按默认):
名称:NotSpider
匹配URL-模式:^$ (正则表达式下^$只代表首页,全站是.*)
条件-条件输入:{HTTP_USER_AGENT}
条件-检查输入字符串是否:与模式不匹配
条件-模式:msnbot|FeedSky|yahoo|Googlebot|Baiduspider|Sosospider|Sogou\ web\ spider|Sosoimagespider|Sogou\ Pic\ Spider|bingbot|YisouSpider|haosou|360Spider|GPTbot
操作-操作类型:中止请求(或者是自定义响应可以阻断请求的状态)